

Missing from this list: an AI that actually fixes the issue →
Connect your tools and ask AI to solve it for you
Introduction to List of Top 12 Vector Databases
Vector databases are revolutionizing how we store and retrieve data in AI and machine learning. Unlike traditional databases that rely on exact matches, vector databases store data as mathematical representations—allowing models to understand context, identify patterns, and make connections. This makes them essential for applications like search, recommendations, and text generation.
According to Gartner, by 2026, more than [30%] of enterprises will have adopted vector databases to build their foundation models with relevant business data.
Additionally, more than 80% of enterprises are expected to use Generative AI APIs or deploy Generative AI-enabled applications by 2026. As AI continues to drive innovation, the need for efficient and scalable vector databases is more crucial than ever.
In this blog, we'll explore the top vector databases available today and what to consider when choosing one for your projects.
Key Features to Consider When Choosing a Vector Database
When selecting a vector database for your machine learning and AI projects, it's essential to consider several key features that ensure optimal performance, scalability, and security.
Here’s a breakdown of the most critical features to look for:
1. High-Dimensional Vector Storage
A robust vector database must efficiently store, manage, and index high-dimensional vector data. This capability is crucial for applications requiring the handling of complex data types, including images, text, and audio. The database should be designed to manage these multidimensional vectors without compromising speed or accuracy.
2. Vector Data Representation and Query Capabilities
Your chosen vector database should support flexible queries, enabling nearest neighbor search, filtering, and hybrid searches that combine vector and non-vector data. This flexibility allows for more sophisticated data retrieval, which is essential for AI models that need to understand and process information contextually.
3. Vector Embeddings
Vector embeddings are a core component of vector databases, translating high-dimensional data into a lower-dimensional space that can be more easily managed and searched. Ensure that the database supports the generation and handling of these embeddings to enhance search and recommendation systems.
4. Scalability and Tunability
As your datasets grow, so does the need for a scalable vector database. Look for a database that can handle expanding data volumes and that offers tunability for specific use cases. This ensures that the database can be fine-tuned to meet the unique demands of your projects, maintaining performance and efficiency as data scales.
5. Multi-Tenancy and Data Isolation
For enterprises managing multiple projects or serving multiple clients, multi-tenancy and data isolation are vital features. A vector database with strong multi-tenancy support allows you to segregate data efficiently, ensuring that each tenant’s data remains isolated and secure.
6. Monitoring and Analytics
Effective monitoring and analytics tools are essential for tracking the performance of your vector database. These tools help identify bottlenecks, optimize performance, and ensure the database operates at peak efficiency, providing insights into query performance and resource utilization.
7. Comprehensive APIs
A vector database with comprehensive APIs allows easier integration into existing workflows and applications. Look for databases that offer RESTful APIs, SDKs, or other interfaces that make it easy to connect with your machine learning and AI frameworks.
8. Intuitive User Interface/Administrative Console
An intuitive user interface and administrative console can significantly reduce the learning curve and operational complexity of managing a vector database. A well-designed interface enables users to quickly navigate, configure, and monitor the database, streamlining the management process.
9. Integrations
Compatibility with machine learning and AI frameworks is a must. The vector database should integrate seamlessly with popular frameworks like TensorFlow, PyTorch, and others, facilitating smooth data flows between your AI models and the database.
10. Indexing and Searchability
Efficient indexing and search capabilities are critical for quickly retrieving relevant data. The database should support various indexing methods and provide fast searchability, particularly for high-dimensional vector data, enabling rapid responses to complex queries.
11. Data Security
Security is paramount when dealing with sensitive data. Look for vector databases that offer robust data encryption, granular access control, and authentication mechanisms to protect your data against unauthorized access and breaches.
12. Cost
Finally, consider the cost of the vector database. Pricing models can vary significantly, from open-source solutions to proprietary options with licensing fees. Evaluate the total cost of ownership, including support, maintenance, and scalability costs, to ensure the database aligns with your budget and long-term needs.
List of Top 12 Vector Databases
- Pinecone
- Milvus
- Chroma
- Weaviate
- Deep Lake
- Qdrant
- Elasticsearch
- Vespa
- Vald
- ScaNN
- Pgvector
- Faiss
Evaluating the Top 12 Vector Databases
Choosing the right vector database is critical for the success of your machine learning and AI projects. Below is a list of some of the top vector databases available today, each with its unique strengths and features that cater to various use cases:
Tools
Pinecone
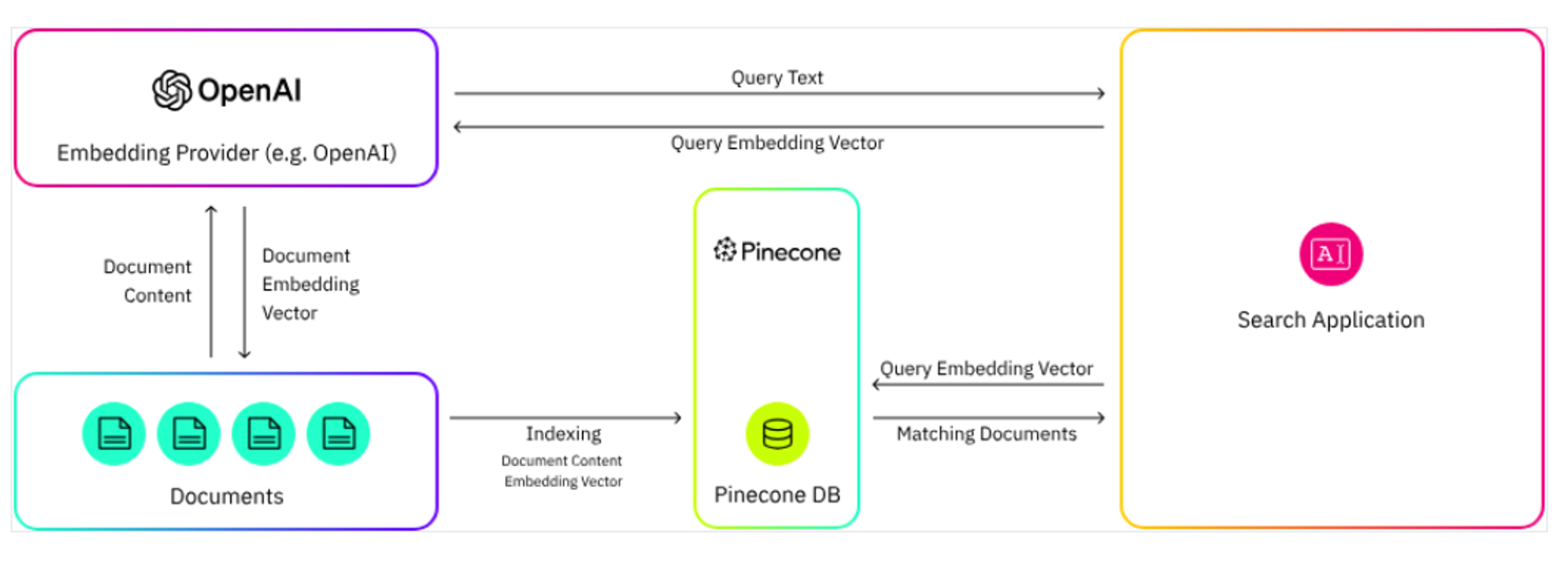
Choosing the right vector database is critical for the success of your machine learning and AI projects. Below is a list of some of the top vector databases available today, each with its unique strengths and features that cater to various use cases:
Benefits
- The serverless design reduces operational costs and complexity, offering seamless integration with existing AI workflows.
- Pinecone streamlines the deployment process by automatically indexing vectors, reducing developers' workload.
- Pinecone offers a user-friendly Python SDK, making it easily accessible to developers and data scientists familiar with the Python ecosystem.
Considerations
- While serverless reduces some costs, ongoing usage can become expensive, especially in large-scale environments.
- While Pinecone is highly effective for similarity search, it may not offer the advanced querying capabilities that some projects might require.
Pricing
Pinecone's pricing starts at $0.096 per hour for the Standard plan and $0.144 per hour for the Enterprise plan, with a free Starter option available. Costs vary based on pod type, size, and cloud provider.
Relevant Links
Docs: https://docs.pinecone.io/
Community: https://community.pinecone.io/
Milvus
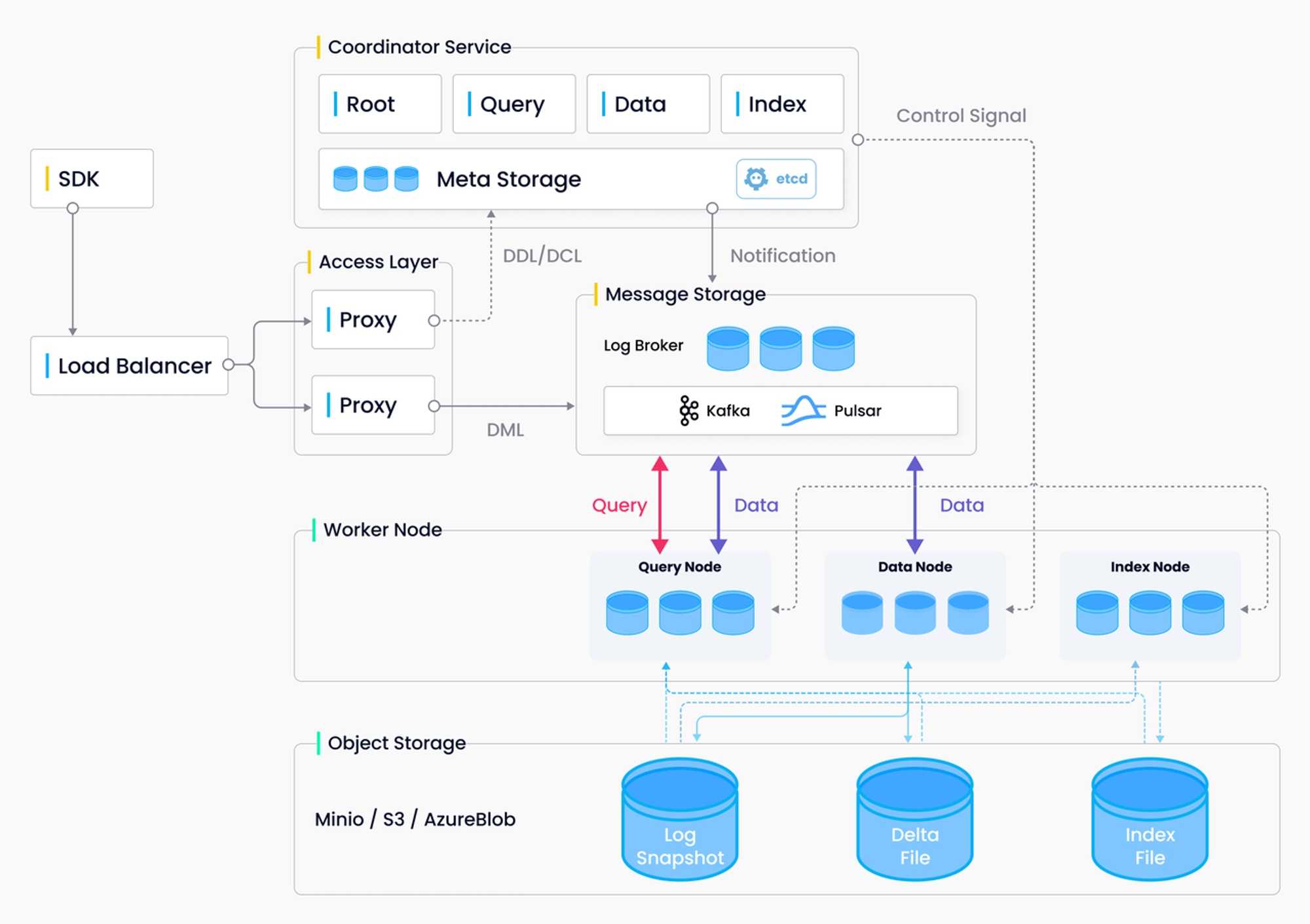
Milvus is a highly flexible, cloud-native, open-source vector database designed for speed and reliability. It enables embedding similarity searches and powers AI applications, making vector databases accessible to all organizations.
Benefits
- Designed to handle massive datasets, Milvus excels in both structured and unstructured data, making it ideal for large-scale AI applications.
- Milvus delivers high-speed vector searches and efficient query handling, which is crucial for AI-driven applications requiring quick data retrieval.

Considerations
- Running Milvus at scale may require significant computational resources, which can increase operational costs.
- While Milvus has a growing community, users might find support limited compared to commercial solutions.
Pricing
Milvus is a 100% free open-source project.
Relevant Links
Chroma
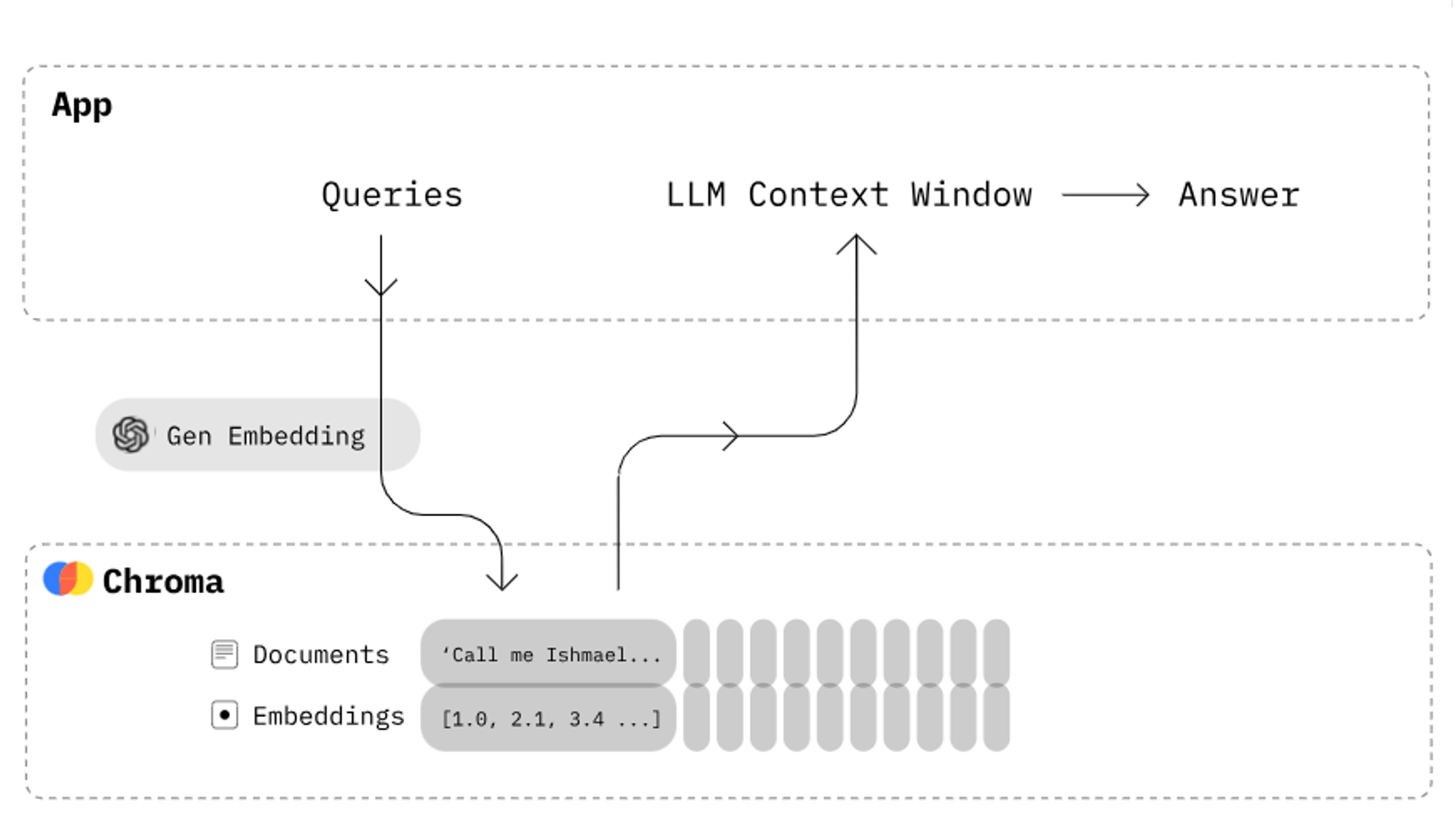
Chroma offers fast and flexible vector search capabilities. It is particularly popular in natural language processing (NLP) applications, where it helps in searching large text corpora and building recommendation engines.
Benefits
- It serves as a vector database for storing embeddings. This allows you to easily create generative AI applications.
- Strong community support
Considerations
Setting up and managing Chroma at scale can require significant effort and a higher level of expertise.
Pricing
Chroma is free and open-source under the Apache 2.0 License.
Relevant Links
Docs: https://docs.trychroma.com/
Weaviate
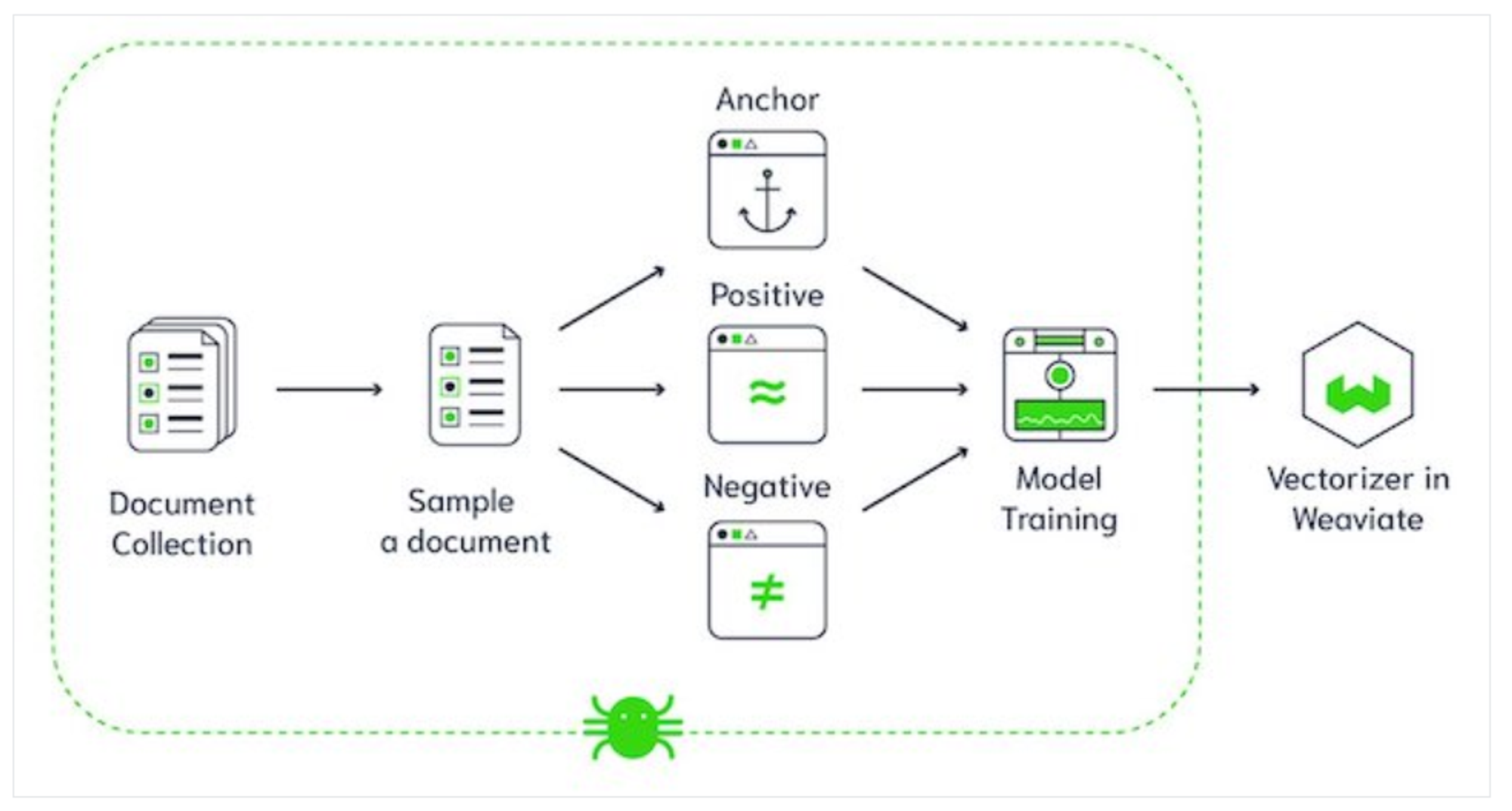
Weaviate is an open-source, AI-native vector database designed to simplify the development and scaling of AI applications for developers at all levels.
Benefits
- Strong emphasis on semantic search, leveraging GraphQL for powerful and flexible querying.
- Provides modules for various data types like text and images, making integration easier.
Considerations
- May experience slower performance with very large datasets or high-throughput scenarios.
- As a relatively newer tool, some features might not be as fully developed.

Pricing
Weaviate's pricing starts at $25/month for 1 million vector dimensions, with a scalable pay-as-you-go model.
Relevant Links
Docs: https://weaviate.io/developers/wcs
Deep Lake
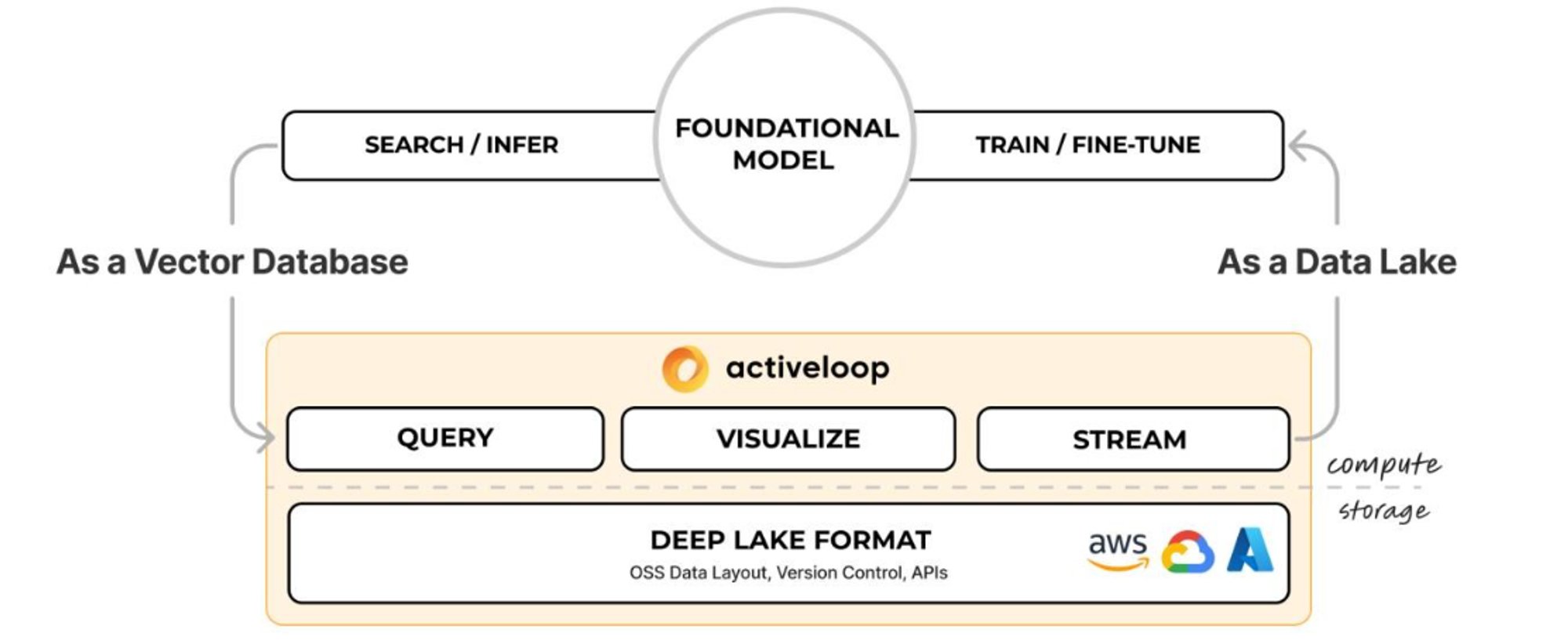
Deep Lake specializes in managing and querying large-scale datasets for AI applications. It is designed to handle high-dimensional vector data efficiently.
Benefits
- Deep Lake is particularly well-suited for deep learning projects that require the storage and retrieval of vast amounts of data.
- Compressed storage
- Integrations with deep learning frameworks
- Distributed transformations
Pricing
Deep Lake offers a free tier with basic features, while paid plans start at $79/month, scaling with usage and advanced features.
Relevant Links
Whitepaper: http://www.deeplake.ai/whitepaper
Qdrant
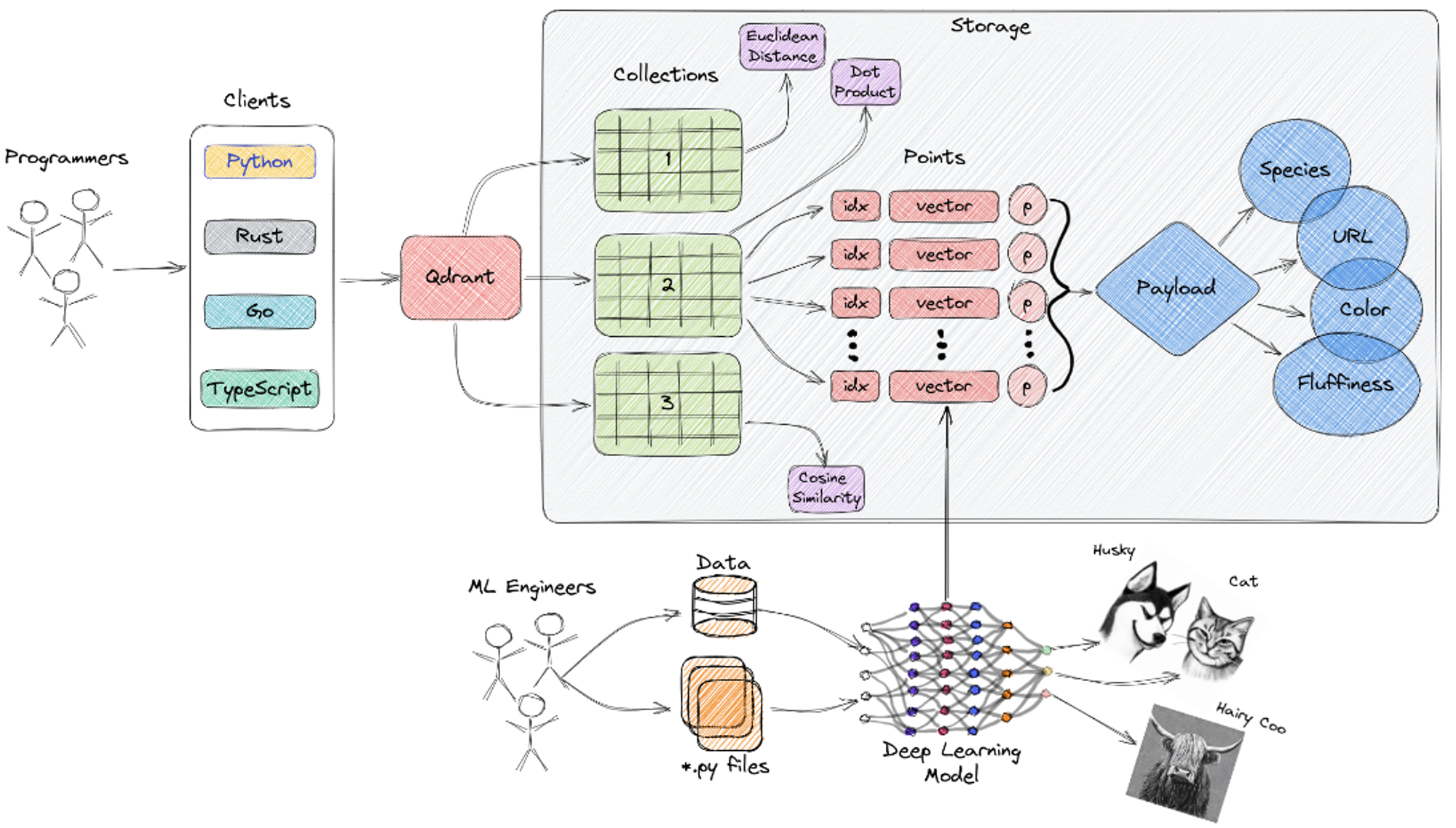
Qdrant is a high-performance vector database optimized for real-time data search and retrieval. It supports filtering and hybrid search, allowing you to combine vector search with traditional database queries. Qdrant is a strong choice for applications that require fast and accurate data retrieval in real-time, such as recommendation engines and AI-powered search systems.
Benefits
- Efficient open-source vector search implementation for containers and Kubernetes.
- Convenient SaaS clustered cloud implementation.
- Benchmarks favorably against other open-source vector search products
- Plenty of integrations and language drivers
- Many options to tweak to optimize your application
Considerations
It has a significant learning curve.
Pricing
Qdrant offers a free tier for small projects, with paid plans starting at $29/month for more advanced features and higher usage.
Relevant Links
Docs: https://qdrant.tech/documentation/overview/#what-are-vector-databases
Elasticsearch
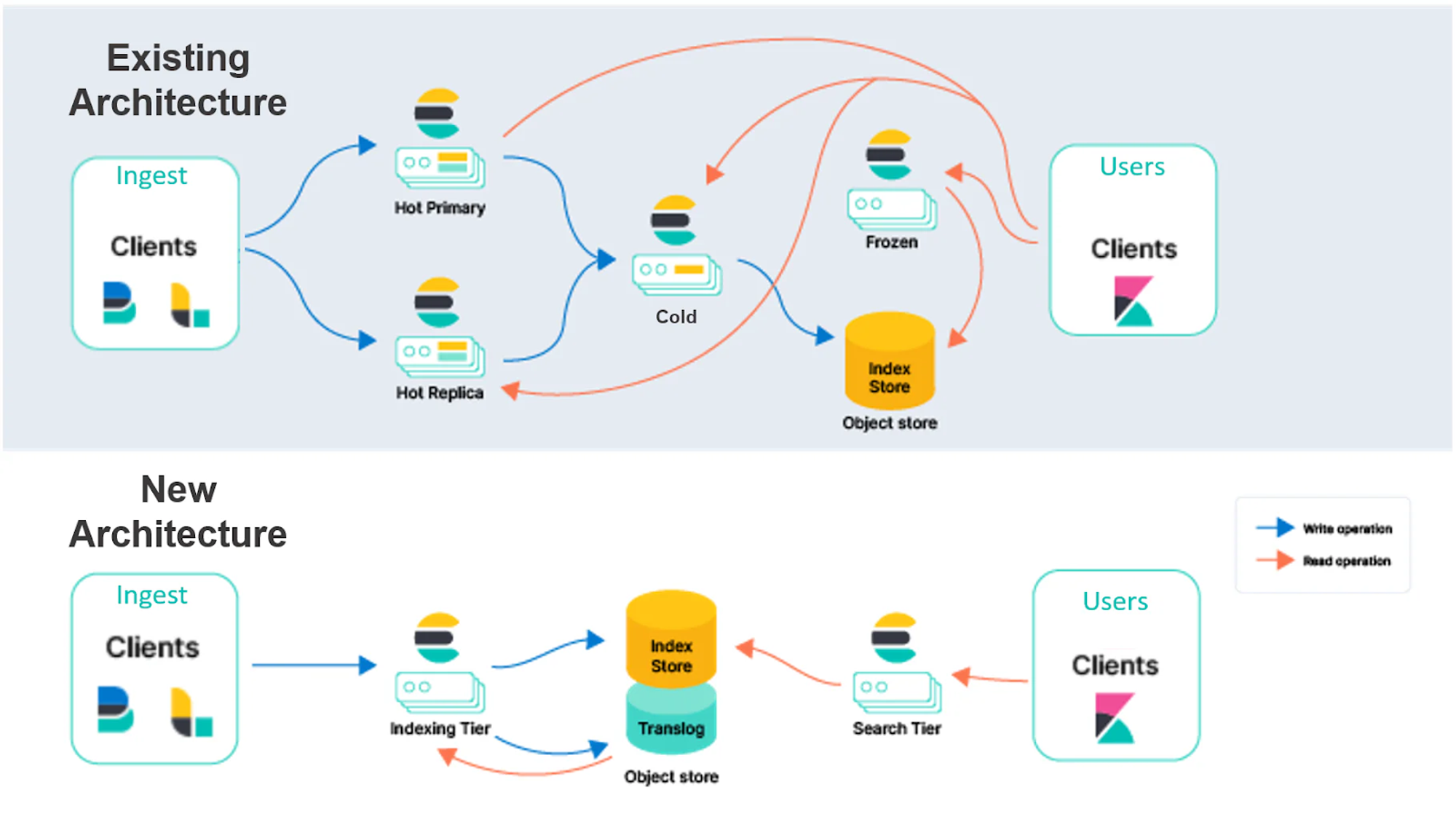
Elasticsearch, widely known as a full-text search engine, also supports vector search through its dense vector field. This capability allows Elasticsearch to perform similarity searches across various data types.
Benefits
- Distributed and Scalable Architecture
- Real-Time Search and Analytics
- Full-text search and Query Flexibility
Considerations
- Complex set-up and maintenance
- A resource-intensive application
- It focuses on enhancing search performance and scalability rather than maintaining strict data consistency and durability.
Pricing
Elastic offers a free basic tier, with paid plans starting at $16/month for additional features and support.
Relevant Links
Docs: https://www.elastic.co/docs
Vespa
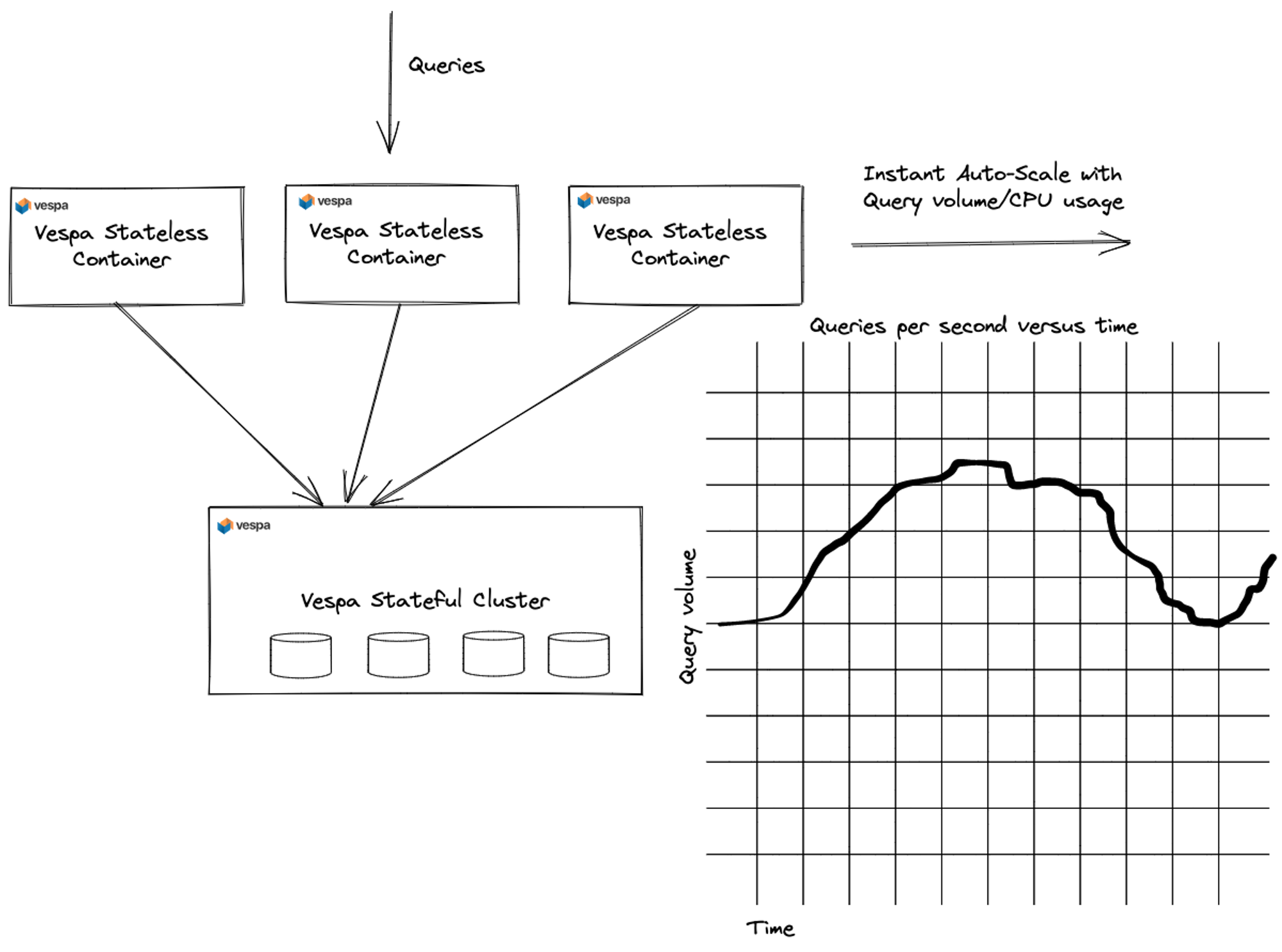
Vespa is an open-source big data processing and serving engine that excels in handling vector search queries at scale.
Benefits
- Vespa’s powerful query language allows users to construct complex similarity searches and tailor queries to specific needs.
- Rich Feature Set: It supports a range of features, including full-text search, structured search, and machine learning-based ranking, providing a comprehensive solution for various search needs.
- Vespa offers significant flexibility in customizing search and recommendation logic to fit unique business requirements.
Considerations
- Smaller-scale deployments are a concern.
- Integrating Vespa with existing systems and workflows can be complex, requiring careful planning and execution.

Pricing
There is no estimate or indication of the pricing given by Vespa.
Relevant Links
Vald
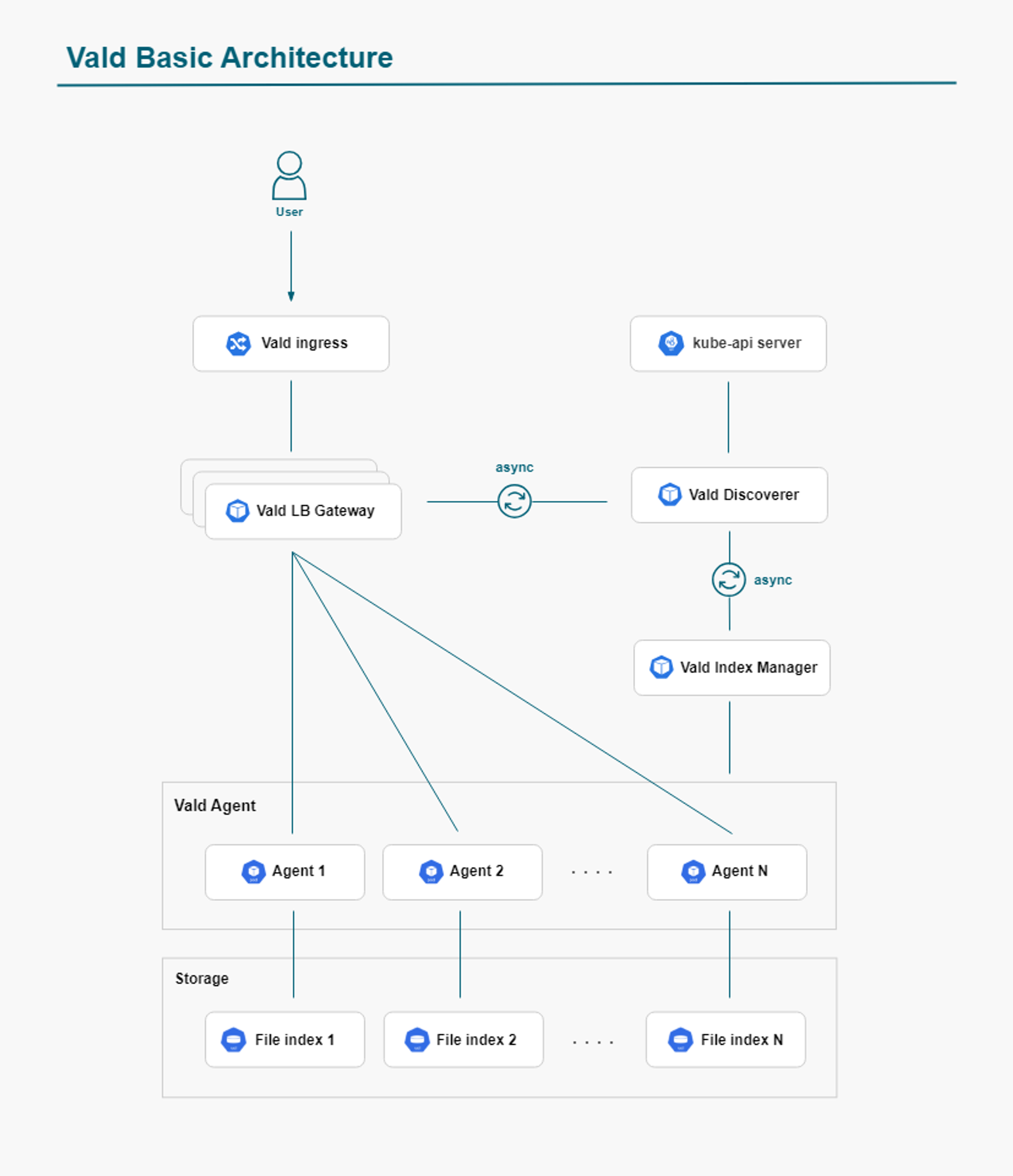
Vald is a scalable and distributed vector search engine that integrates well with Kubernetes. It offers high-speed, low-latency searches across large datasets, making it a great option for cloud-native applications. Vald’s compatibility with Kubernetes ensures seamless scaling and management of vector data, even in the most demanding environments.
Benefits
Built for deployment on Kubernetes, it aligns with contemporary cloud infrastructure and takes advantage of its benefits.
Considerations
- Since indexes are stored in memory, it necessitates a significant amount of memory.
- Frequent system locks during commit operations as the data size increases.
Pricing
Vald is an open-source project with no direct pricing, but deployment costs depend on your infrastructure.
Relevant Links
ScaNN
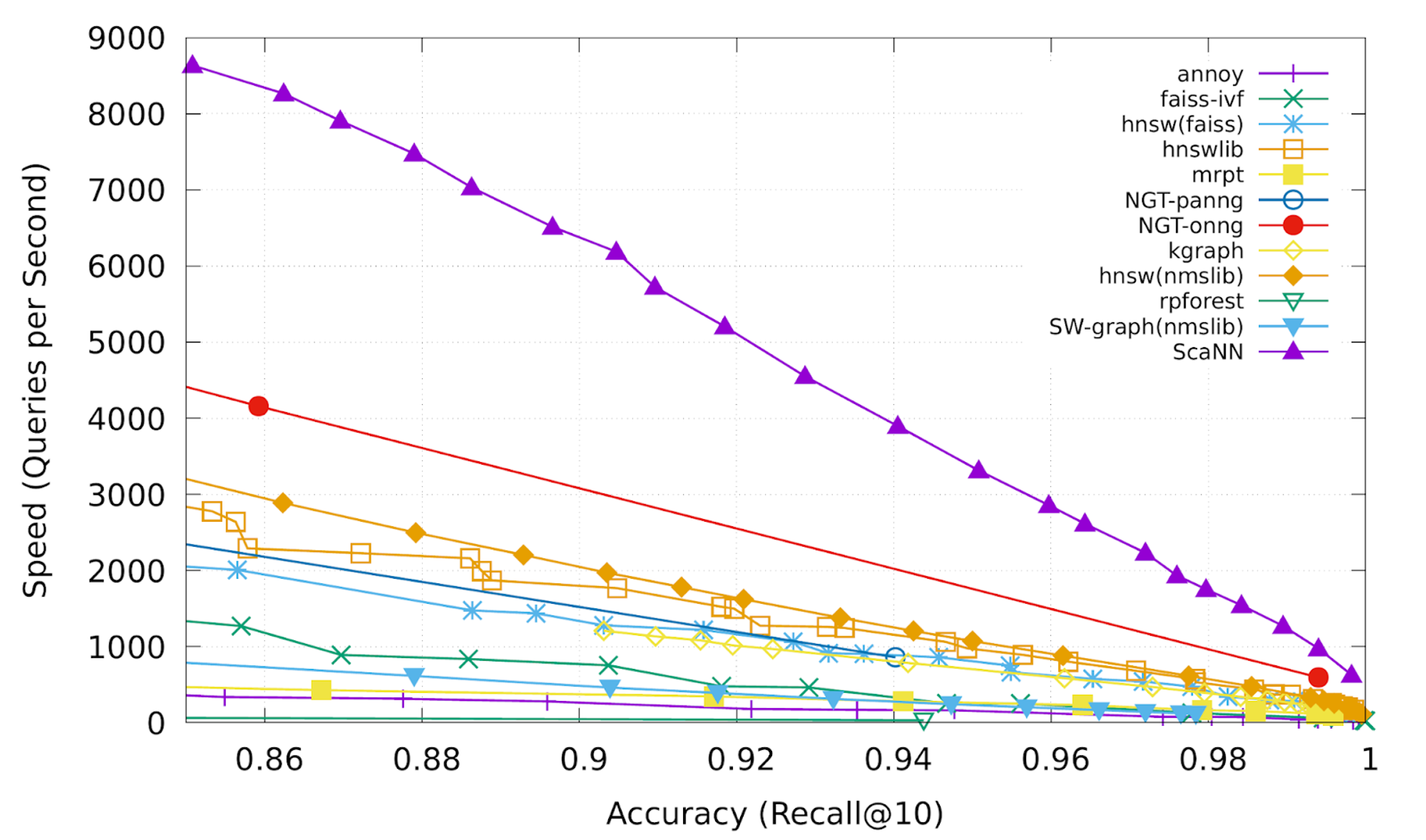
ScaNN (Scalable Nearest Neighbors) is a vector search library developed by Google. It is designed for high-throughput, low-latency similarity search, making it suitable for AI applications that require fast and efficient data retrieval. ScaNN’s integration with TensorFlow and other Google AI tools makes it an excellent choice for developers already working within the Google ecosystem.
Benefits
- Smaller memory footprint
- Faster index build times
- Higher writer throughput
- Full PostgreSQL compatibility
Pricing
There is no estimate or indication of the pricing given by SacNN.
Relevant Links
GitHub: https://github.com/google-research/google-research/tree/master/scann
Pgvector
Pgvector is an extension for PostgreSQL that adds support for vector data types. It enables vector similarity searches directly within PostgreSQL, allowing you to leverage the power of vector search without needing a separate database system.
Benefits
PG Vector seamlessly embeds machine learning into PostgreSQL.
Considerations
- As data complexity grows, configuring and tuning PG Vector requires significant resources and expertise.
- Managing the system becomes increasingly challenging as datasets expand and become more complex.
Pricing
There is no estimate or indication of the pricing given by Pgvector.
Relevant Links
Faiss
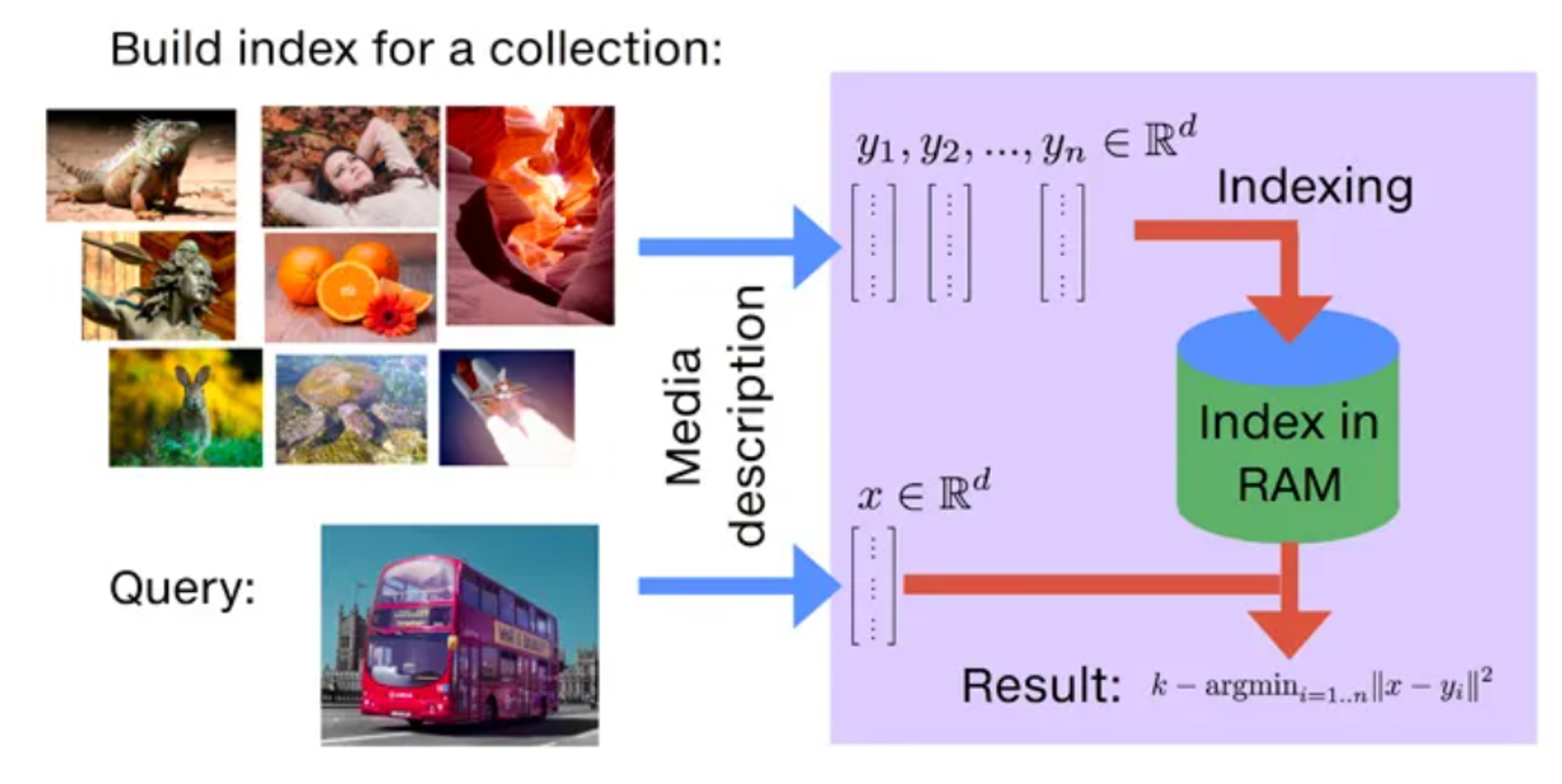
Faiss (Facebook AI Similarity Search) is a library developed by Facebook AI Research for efficient similarity search and clustering of dense vectors. It is optimized for both CPU and GPU, making it capable of handling large-scale vector search tasks.
Benefits
FAISS employs vector representations for data points and conducts approximate nearest-neighbor searches to identify similar items, resulting in faster search times and lower memory consumption compared to conventional approaches.
Considerations
It may face scalability issues when dealing with large datasets that exceed available RAM.
Pricing
There is no estimate or indication of the pricing given by Faiss.
Relevant Links
Conclusion



When selecting a vector database for your AI and machine learning projects, the right choice depends on your specific needs and scale.
If you're just starting out or have smaller-scale requirements, options like Chroma or Milvus offer excellent open-source solutions with minimal costs. For those needing a fully managed, high-performance solution with quick time-to-value, Pinecone or Qdrant might be ideal.
If you prefer a flexible, open-source platform that you can customize and scale internally, solutions like Weaviate or Vald could be perfect for you. Each tool offers unique strengths, so aligning your choice with your project's demands is key to success.
Missing from this list: an AI that actually fixes the issue →
Connect your tools and ask AI to solve it for you
Ready to cut the alert noise in 5 minutes?
Install our free slack app for AI investigation that reduce alert noise - ship with fewer 2 AM pings
Frequently Asked Questions
Everything you need to know about observability pipelines